
こんにちは!
事務職出身RPAエンジニアのMです。
今回はSynchRoidの「コマンドライン実行」ステップを使い、PDFファイルの総ページ数を取得する方法をご紹介します。
先日、PDFファイルの総ページ数によって処理を変えるロボットを作成しました。
その際に悩んだのがPDFファイルのページ数を抽出する部分です。
SynchRoid では「PDFから抽出」ステップでPDFのテキスト等を抽出することができますが、総ページ数を抽出することはできません。
どう対応するか検討した結果、Windowsの機能であるPowerShellと「コマンドライン実行」ステップを組み合わせてページ数を抽出する方法に辿りつきました。
Windows10以降であればPowerShellは標準機能なので、新たにツールやアプリをインストールすることなく実践できます。
また、この方法はSynchRoidのベースとなっているRPAツールBizRobo!でも使うことができます。
ではさっそく開発手順に沿って解説していきます。
※この記事のロボット作成で使用しているSynchRoidのバージョンは ライトパック 10.7.0.4 です。
目次
変数を準備する
まずこのロボットで使用する4つの変数を作成します。
| 変数名 | 変数のタイプ | デフォルト値 |
|---|---|---|
| フォルダパス | Short Text | ページ数を取得したいPDFファイルが格納されているフォルダのパスを記入 |
| PDFファイル名 | Short Text | (空白) |
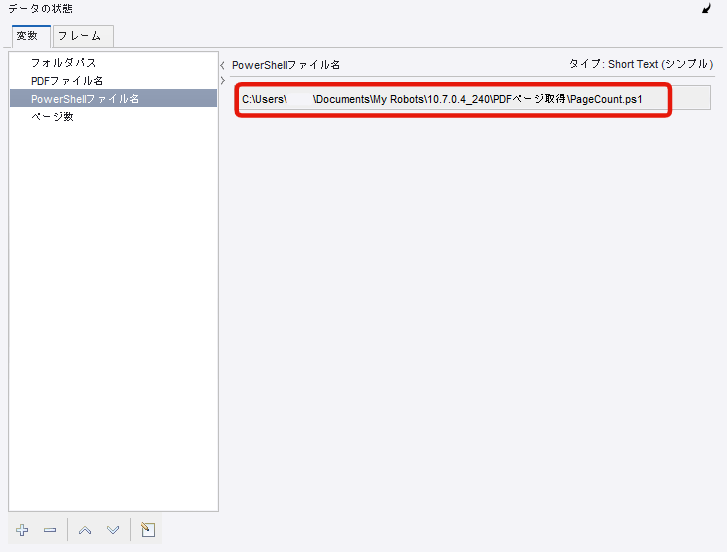
| PowerShellファイル名 | Short Text | PowerShellファイルの出力先を「.ps1」の拡張子を含めたフルパスで記入※ |
| ページ数 | Short Text | (空白) |
※PowerShellファイルのファイル名を「PageCount.ps1」として今回は設定しました。
PDFファイルのファイル名を取得する
複数ファイルでも対応できるよう、任意のフォルダ内にあるPDFファイルをループで順に処理していくという工程にしました。
1.「ファイル繰り返し」ステップの設定
まず、PDFファイルのファイルパスを取得するため「ファイル繰り返し」ステップを追加し設定します。
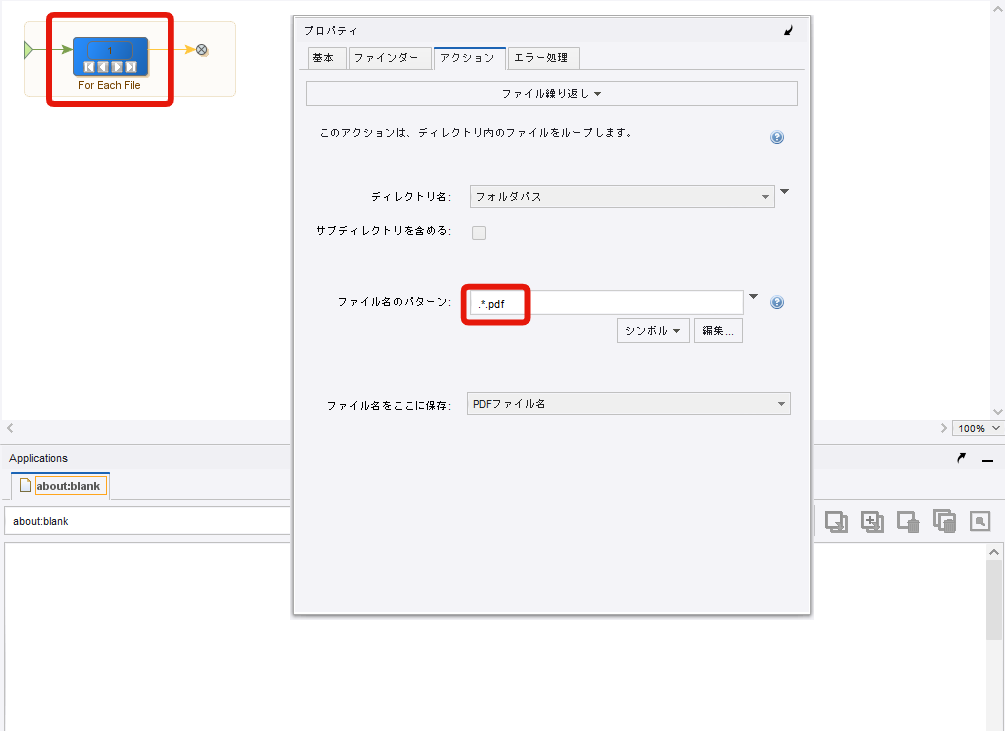
「ディレクトリ名」に変数『フォルダパス』を設定してください。
PDFファイルを読み込むので、ファイル名のパターンには「.*.pdf」と入力します。※画像プロパティの赤枠
「ファイル名をここに保存」は変数『PDFファイル名』を選択します。
2.「変数の割当」ステップの設定
「ファイル繰り返し」ステップで取得したファイルパスからPDFファイル名を抽出するため、「変数の割当」ステップを設定します。
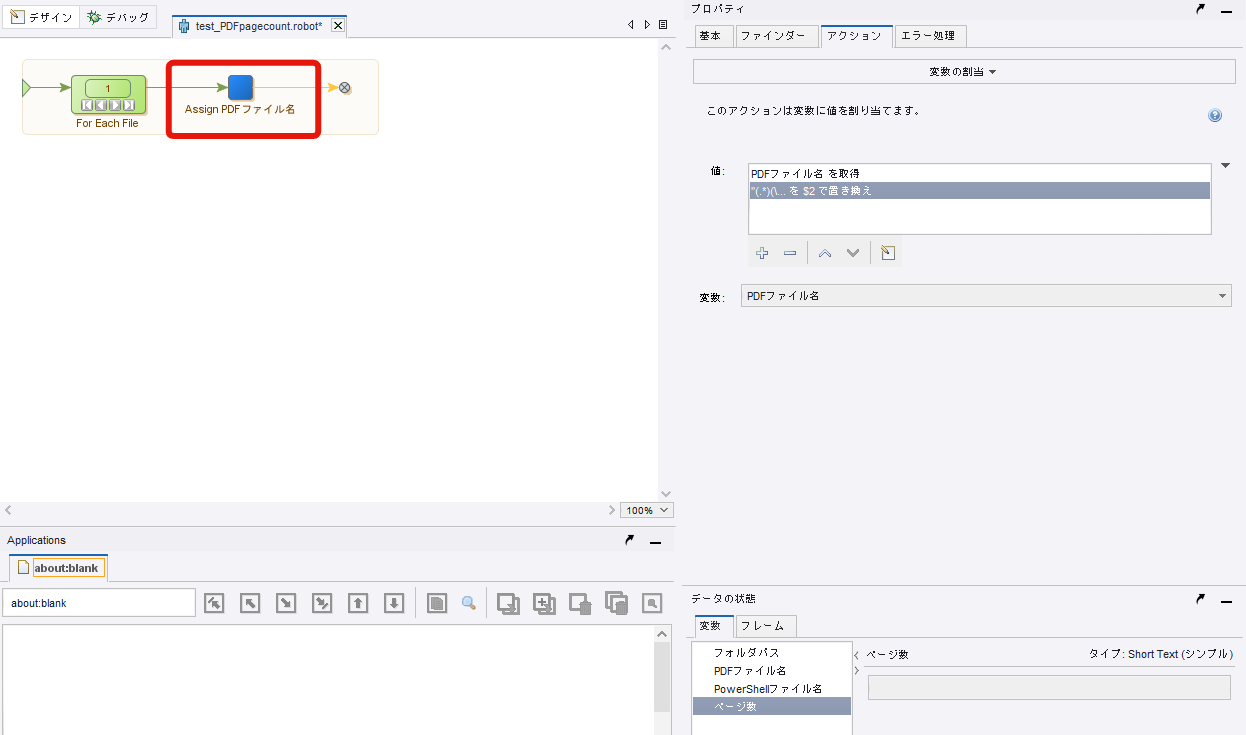
値は「コンバータ」を選択し、変数を取得で『PDFファイル名』を選択します。
抽出から「高度な抽出」を選択し、編集ボタンから「パターン」の設定を行います。
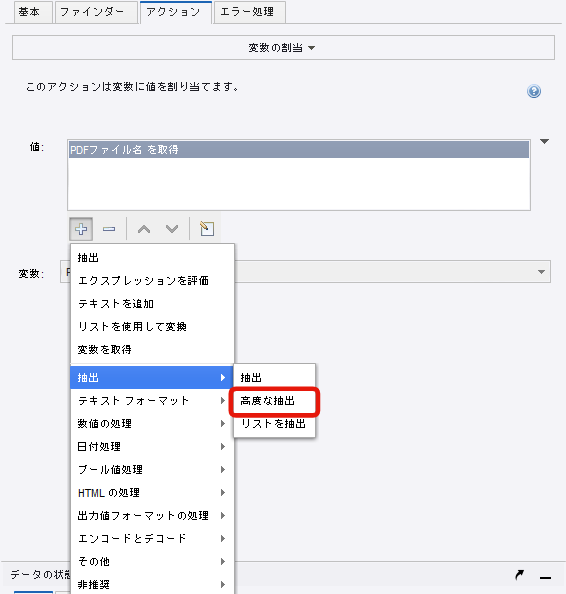
拡張子の「.pdf」を含めたファイル名を抽出したいので、パターンには「(.*)\\(.*.pdf)」と入力してください。
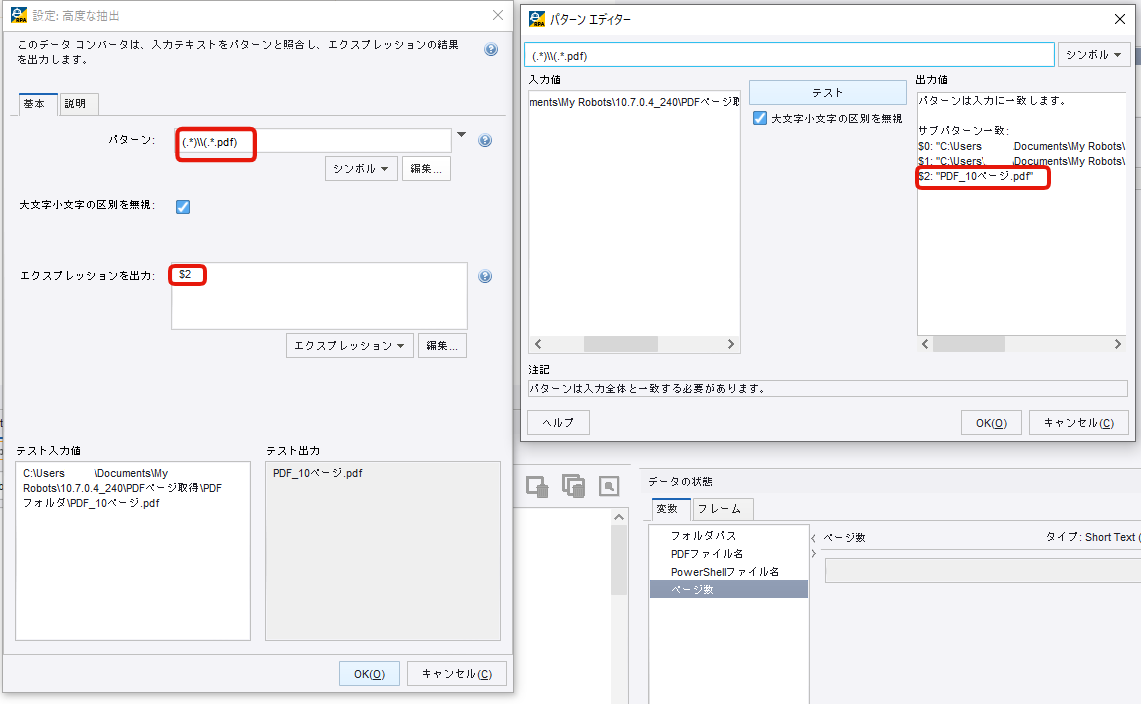
エクスプレッションを出力にはサブパターンの「$2」を指定します。
これでファイル名の抽出は完了です。
PowerShellファイルを出力する
コマンドライン実行で使用するPowerShellファイルを出力します。
「ファイル出力」ステップを追加し設定します。
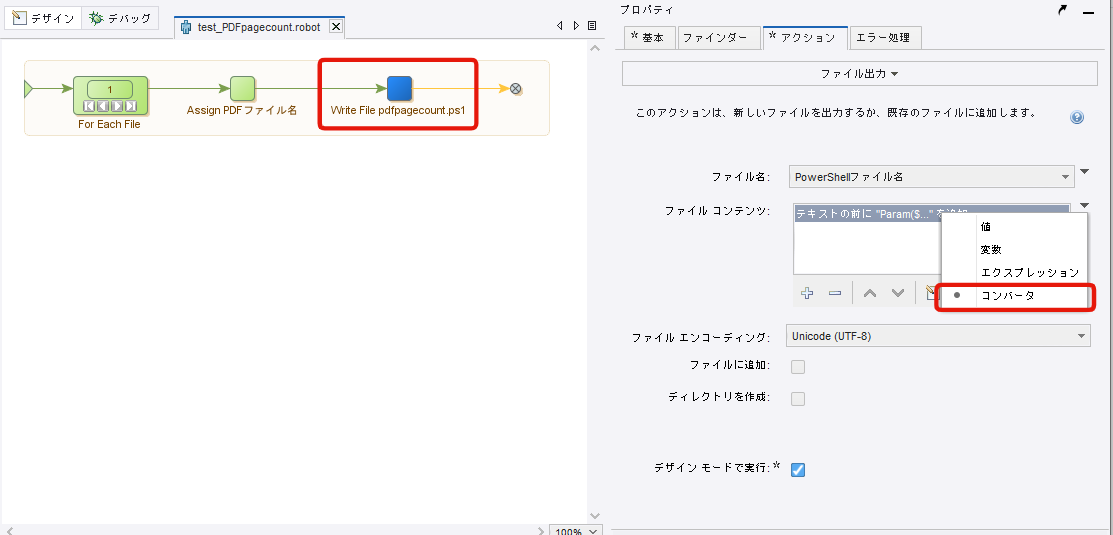
ファイル名には変数『PowerShellファイル名』 を選択してください。
ファイルコンテンツはコンバータを選び、テキストフォーマットから「テキストを追加」を選択してください。
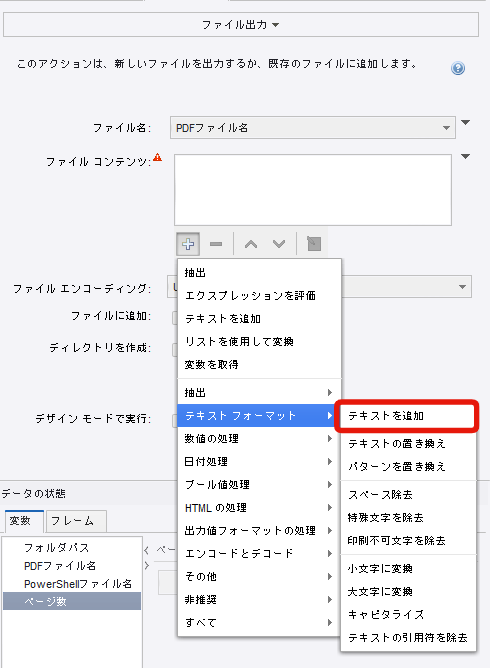
追加するテキストの記入欄に以下のPowerShellスクリプトを貼り付けてください。
Param($theFilePath, $thePassword)
[Windows.Data.Pdf.PdfDocument,Windows.Data.Pdf,ContentType=WindowsRuntime] | Out-Null
Add-Type -AssemblyName System.Runtime.WindowsRuntime
$asTaskGeneric = ([System.WindowsRuntimeSystemExtensions].GetMethods() | ? { $_.Name -eq 'AsTask' -and $_.GetParameters().Count -eq 1 -and $_.GetParameters()[0].ParameterType.Name -eq 'IAsyncOperation`1' })[0]
Function Await($WinRtTask, $ResultType) {
$asTask = $asTaskGeneric.MakeGenericMethod($ResultType)
$netTask = $asTask.Invoke($null, @($WinRtTask))
$netTask.Wait(-1) | Out-Null
$netTask.Result
}
[Windows.Storage.StorageFile,Windows.Storage,ContentType=WindowsRuntime] | Out-Null
$theFile = Await ([Windows.Storage.StorageFile]::GetFileFromPathAsync($theFilePath))([Windows.Storage.StorageFile])
$thePdfDocument = Await ([Windows.Data.Pdf.PdfDocument]::LoadFromFileAsync($theFile, $thePassword))([Windows.Data.Pdf.PdfDocument])
$thePdfDocument.PageCount
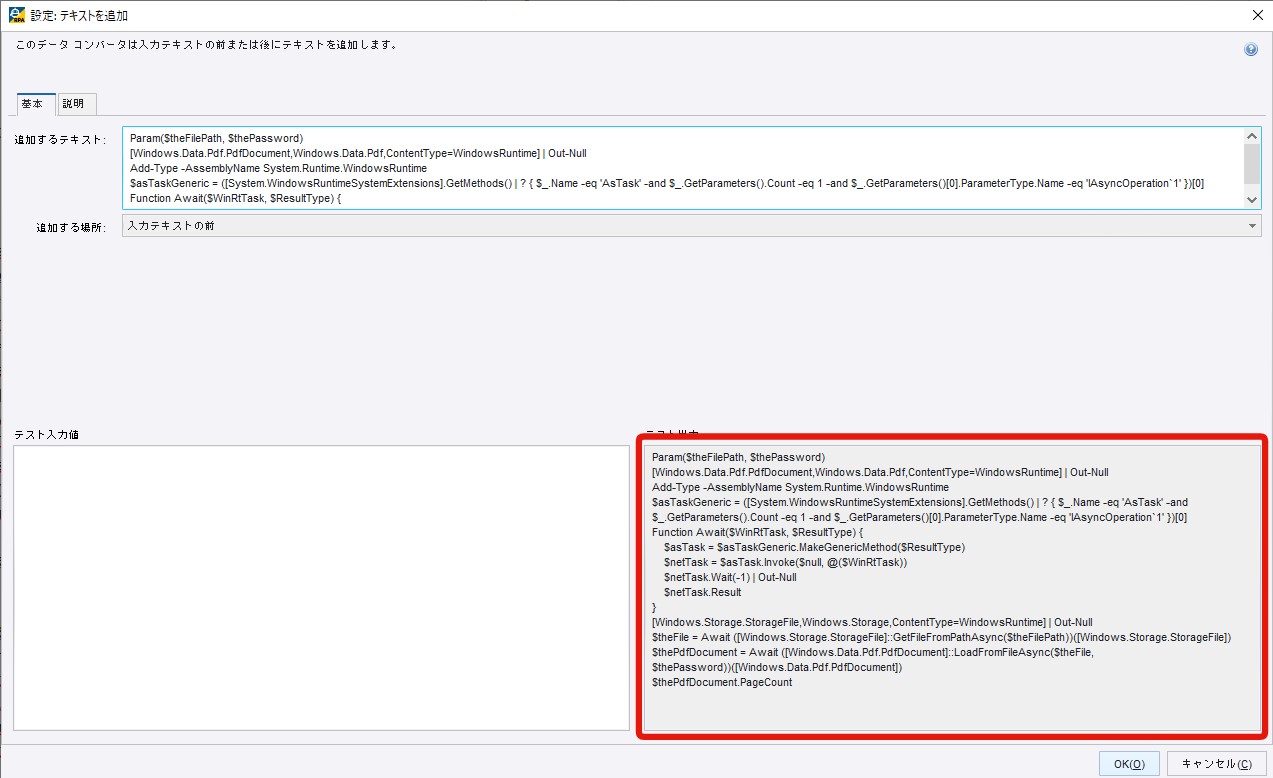
これでPowerShellファイルの準備が終わりました。
PowerShellスクリプトの解説
PowerShellになじみのない方には何だか暗号のように感じられるかもしれません。
最初はおまじないのようなものと考えてしまって大丈夫です。
スクリプトの内容を大まかに解説します。
(1)PowerShell スクリプトの引数を定義
Param($theFilePath, $thePassword)
(2)WindowsRuntime 読込み
[Windows.Storage.StorageFile, Windows.Storage, ContentType = WindowsRuntime] | Out-Null
(3)非同期メソッドを同期的に扱うための関数を定義
Add-Type -AssemblyName System.Runtime.WindowsRuntime
$asTaskGeneric = ([System.WindowsRuntimeSystemExtensions].GetMethods() | ? { $_.Name -eq 'AsTask' -and $_.GetParameters().Count -eq 1 -and $_.GetParameters()[0].ParameterType.Name -eq 'IAsyncOperation`1' })[0]
Function Await($WinRtTask, $ResultType) {
$asTask = $asTaskGeneric.MakeGenericMethod($ResultType)
$netTask = $asTask.Invoke($null, @($WinRtTask))
$netTask.Wait(-1) | Out-Null
$netTask.Result
}
(4)WindowsRuntime 読込み
[Windows.Data.Pdf.PdfDocument, Windows.Data.Pdf, ContentType = WindowsRuntime] | Out-Null
(5)ファイル取得
$theFile = Await ([Windows.Storage.StorageFile]::GetFileFromPathAsync($theFilePath))([Windows.Storage.StorageFile])
(6)PDFオブジェクト取得
$thePdfDocument = Await ([Windows.Data.Pdf.PdfDocument]::LoadFromFileAsync($theFile, $thePassword))([Windows.Data.Pdf.PdfDocument])
(7)ページ数をカウント
$thePdfDocument.PageCount
コマンドライン実行ステップの設定
出力したPowerShellを実行するため、「コマンドライン実行」ステップを追加して設定します。
「データを保存」には最初に準備した変数『ページ数』を選択します。
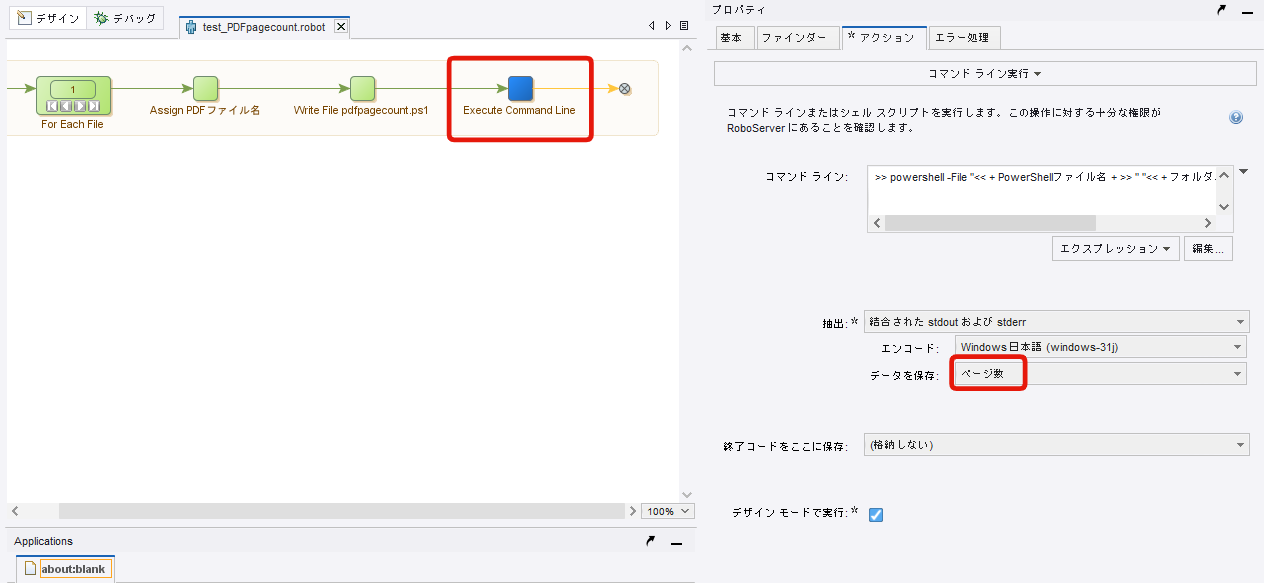
コマンドラインはエクスプレッションを使用します。
記入するコマンドはこちらです。
>> powershell -File "<< + PowerShellファイル名 + >> " "<< + フォルダパス + >>\<< + PDFファイル名+ >>"<<
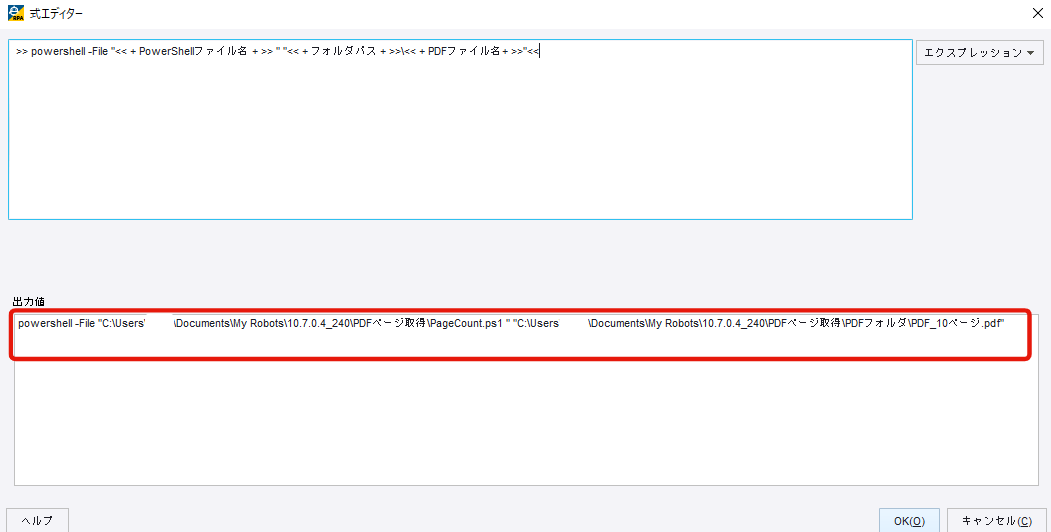
ここまでに設定した変数から、画像赤枠のコマンドが出力値に設定されます。
「コマンドライン実行」ステップを進めて、変数『ページ数』にPDFファイルのページ数が抽出されることを確認してください。
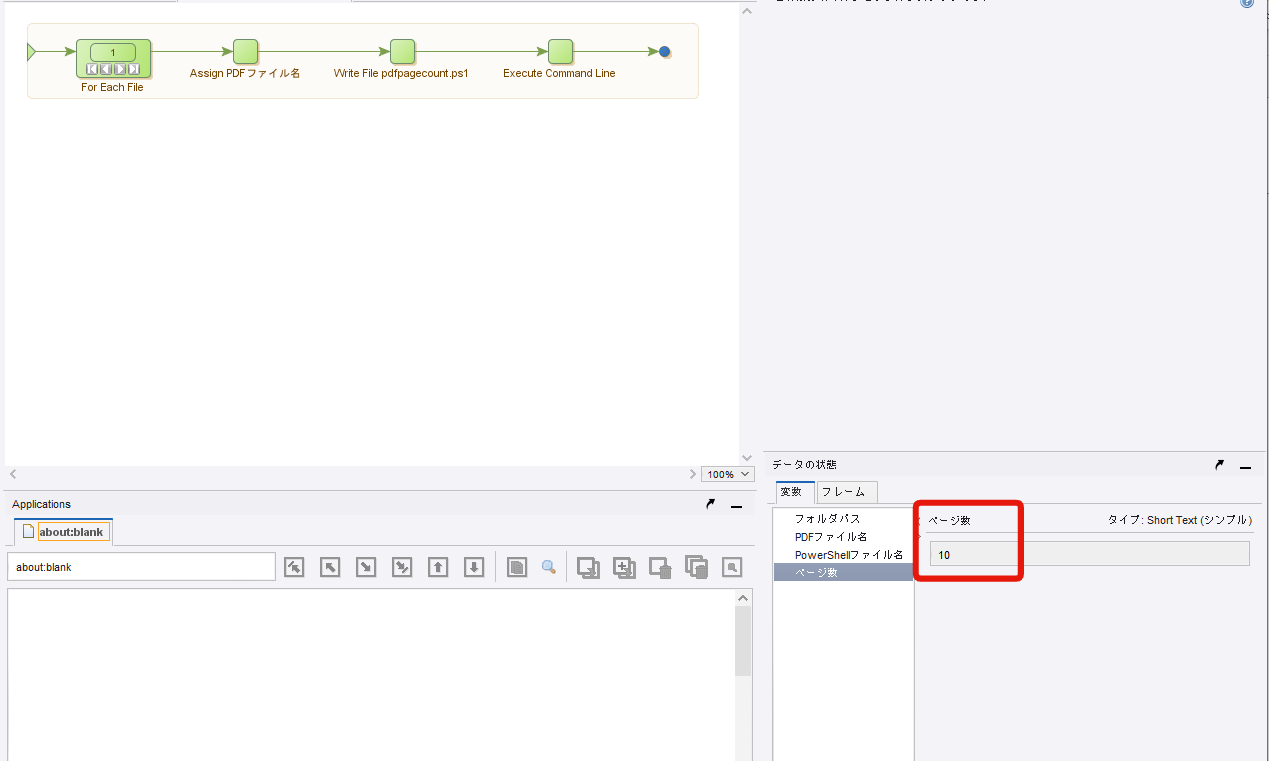
ページ数の抽出
先ほど抽出したページ数ですが、実は数字の後ろにスペースが含まれています。
このままでは使い勝手が悪いので、数字だけ抽出するため「変数の設定」ステップを追加します。
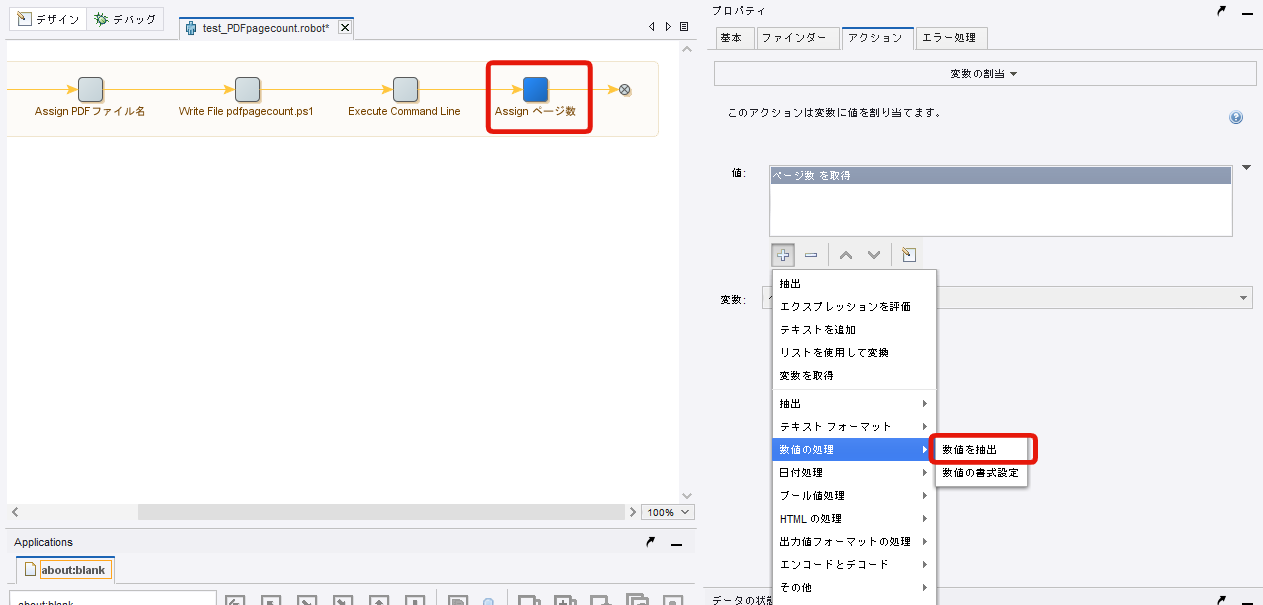
値は「コンバータ」を選択し、変数を取得で『ページ数』を選択します。
数値の処理から「数値を抽出」を選択し「整数に変換」にチェックを入れます。
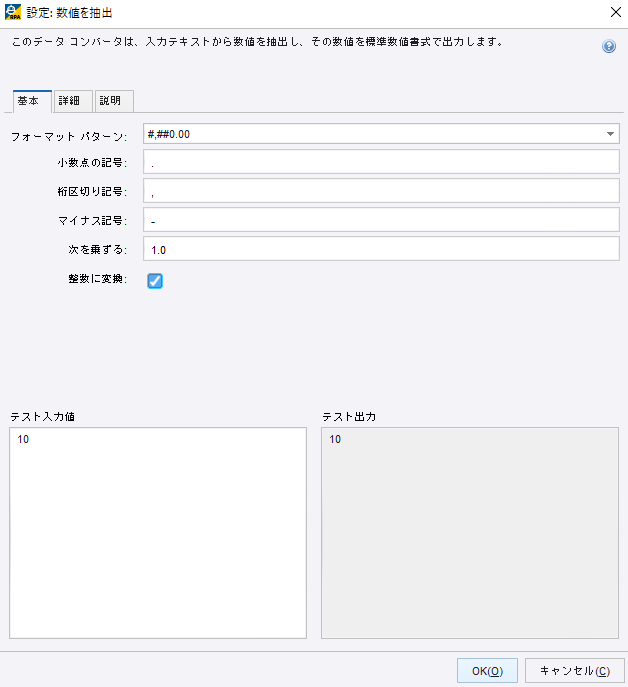
これでページ数の数値の部分だけを抽出することができました!
まとめ
今回はPowerShellとの組合せでPDFのページ数を取得する方法を解説しました。
ポイントはPowerShellファイルを出力し、「コマンドライン実行」ステップで出力したファイルを実行するという手順です。
この解説ではPowerShellを使用しましたが、VBSでも同様の手順でページ数を取得することが可能です。
「コマンドライン実行」ステップを活用できるようになるとSynchRoidの可能性がより広がりますね!
これからもちょっとしたテクニックなど、SynchRoid開発のお役に立てるような情報を発信していく予定です。
具体的な開発アドバイスが欲しい方はぜひ、タクトシステムのRPA導入支援サービス「ハカドリRPA」をご検討ください。
伴走型サポートをコンセプトにした「ハカドリRPA」では皆さまのロボット開発を手厚くサポートします。
ぜひタクトシステムまでお気軽にご相談ください。
次回:「SynchRoid PDFのページ数により格納場所を振り分ける」
\うまくいかないRPAでお悩みなら/
![]()
RPAのロボット作成代行
導入、運用・メンテナンス、乗り換えを伴走サポート
RPAツールSynchRoidをはじめ、複数のRPAツール導入支援を行っています。

